Mindset & Intent
ENGINEERING IDENTITY
Professional Profile & Technical Background
A DevOps and Platform Engineer focused on building reliable, automated cloud infrastructure and scalable deployment systems.
My technical foundation is built on hands-on infrastructure work, covering cloud architecture, container orchestration, deployment automation, and system monitoring across real environments.
I build with a focus on cloud-native patterns, CI/CD integration, observability pipelines, and access security — with attention to how components behave together under load.
I approach distributed systems by breaking down complexity, understanding how things fail, and learning to fix them to maintain consistent service availability.
Every deployment decision considers observability, scalability, and long-term maintainability — ensuring systems remain operable as workloads and requirements evolve.
I reduce manual work by building reliable automation workflows that improve deployment consistency and reduce intervention across the infrastructure lifecycle.
I apply the same engineering standards to development and test environments as to production — because system behavior in validation directly affects production outcomes.
Engineering Philosophy
"Reliable systems are built through infrastructure automation, continuous observability, and consistent operational discipline."
Operational_Bias
Focused on building platform systems that support service reliability, security controls, and consistent scalability — starting from strong fundamentals and growing from there.
Technical skills develop through implementation, hands-on testing, and iterative refinement across varied infrastructure and deployment environments.
Engineering Capabilities
OPERATIONAL SCOPE
Core Skills & Technical Expertise
AWS Cloud Infrastructure & DevOps Engineering
- Cloud Architecture: Designing and provisioning VPC environments, EKS clusters, and cloud networking on AWS.
- Kubernetes Orchestration: Deploying and managing containerized workloads and microservices across Kubernetes clusters.
- CI/CD Automation: Building GitOps-based deployment pipelines to automate the software delivery process.
- Infrastructure as Code: Provisioning and managing cloud resources using version-controlled IaC with Terraform.
- Architectural Validation: Applying AWS architecture best practices as an AWS Certified Solutions Architect – Associate.
AI Systems & LLM Infrastructure
- Private AI Deployment: Hosting and running self-managed LLM platforms on Kubernetes with optimized compute configurations.
- Resource-Optimized Infrastructure: Designing compute environments suited to resource-constrained and bare-metal deployments.
- Workflow Automation: Building custom tooling and AI-assisted workflows to support software development processes.
- System Analysis: Using AI-assisted approaches to document, review, and improve complex system designs.
Distributed Systems & Application Development
- Platform Interfaces: Building responsive frontends using Next.js to interact with cloud service backends.
- Backend Services: Developing API layers and service communication using NestJS and Node.js.
- Data Layer: Configuring relational and NoSQL databases with caching strategies for persistent, scalable storage.
- End-to-End Reliability: Connecting application layers with infrastructure to maintain consistent system behavior and user experience.
Cloud Security & DevSecOps
- Network Security: Configuring network segmentation, security groups, and encrypted communication between services.
- Identity & Access Management: Applying IAM policies and role-based access controls across cloud environments.
- Compliance & Governance: Structuring infrastructure to meet security standards and operational requirements.
Observability & Site Reliability Engineering
- System Monitoring: Implementing metrics, dashboards, and health checks for distributed service environments.
- Centralized Logging: Configuring log aggregation pipelines for visibility into application and infrastructure behavior.
- Reliability Operations: Monitoring system performance, identifying bottlenecks, and contributing to service availability.
These areas reflect a consistent focus on infrastructure automation, deployment reliability, and platform operations. The goal is building systems that are observable, maintainable, and built to scale.
TECHNOLOGY STACK
CLOUD PLATFORMS
Working with AWS, GCP, and Azure to provision cloud environments, manage networking, and configure core platform services.
CONTAINERS & ORCHESTRATION
Building and running containerized applications using Docker, managing workload deployment and scaling with Kubernetes.
CI/CD & AUTOMATION
Designing deployment pipelines and infrastructure automation workflows to support continuous integration and delivery.
OBSERVABILITY
Setting up monitoring, logging, and alerting systems to track service health and investigate issues in distributed environments.
SECURITY & ACCESS
Applying IAM policies, secret management, and security scanning to control access and maintain a secure infrastructure posture.
AI & ENGINEERING TOOLS
Using AI-assisted tools to support infrastructure planning, code review, documentation, and development efficiency.
Certifications & Learning
VALIDATION LAYERS
Tools, Certifications & Tech Stack
My technical knowledge is developed through a combination of structured study and hands-on implementation. Industry certifications provide a reference framework, which is then validated through actual infrastructure deployments and system-level projects.
I build operational understanding iteratively: concepts are prototyped in sandbox environments, tested under realistic conditions, and refined through practical troubleshooting.
Beyond certification coverage, I focus on understanding how systems work at the component level — including failure behavior, performance characteristics, and operational trade-offs.
I stay current by following evolving DevOps practices and cloud-native patterns through continuous self-directed learning and hands-on experimentation.
Applied Methodology
I follow an applied learning methodology — infrastructure patterns are reinforced through direct implementation, continuous testing, and iterative refinement rather than passive study.
Each engineering cycle covers: system design, infrastructure provisioning, failure analysis, performance review, and documentation of findings.
I test platforms under simulated failure conditions and varied observability configurations to build a practical understanding of system behavior under stress.
This approach develops an SRE-aligned perspective — focused on system reliability, operational visibility, and maintainable infrastructure design.
AWS Certified Solutions Architect – Associate
Amazon Web Services // 2024
Validates knowledge of AWS services, cloud architecture patterns, secure networking, and designing scalable, cost-effective cloud solutions.
AWS & DevOps Professional Training Program
Structured Certification Track
Completed a structured training program covering infrastructure automation, CI/CD pipeline design, container orchestration, and core DevOps practices.
Diploma in AWS with Python
Academic Certification Program
Completed an AWS-focused program covering cloud infrastructure fundamentals, Python-based automation scripting, and cloud resource management.
Upcoming Infrastructure Validation Queue
Active Focus Areas
Active learning areas include SRE practices, security automation, Kubernetes cluster management, and distributed systems reliability.
Featured Projects
ENGINEERING WORK
Projects & Hands-On Implementations
LearnSphere
Foundation Infrastructure — Single-AZ AWS Setup
How do you validate enterprise-grade infrastructure patterns — Kubernetes orchestration, GitOps delivery, and observability — without production-level budgets?
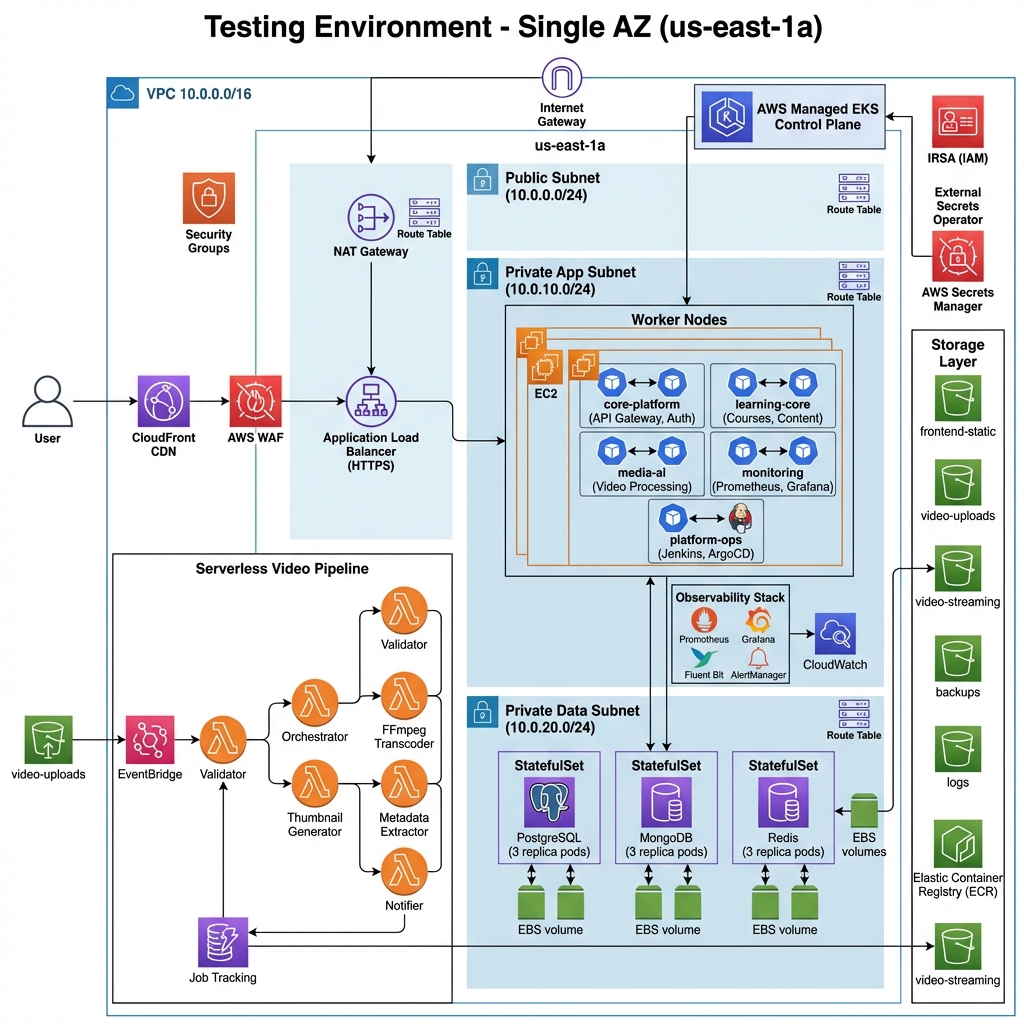
LearnSphere is a self-hosted learning platform built to validate core infrastructure patterns in a controlled environment. The system uses a microservices architecture where each service runs in its own container, enabling focused testing of infrastructure components including identity management, media processing, and service observability. The infrastructure is scoped to a single AWS Availability Zone to cover the full deployment lifecycle while managing cost. This setup supported hands-on work with Kubernetes cluster configuration, VPC networking, CI/CD pipeline design, and monitoring — without the complexity of multi-AZ failover. A key focus was automating infrastructure provisioning and deployment workflows. The project includes an event-driven media processing pipeline using serverless functions, and all cloud resources are managed using Infrastructure as Code to maintain consistency across environments.
ARCHITECTURE VISUALIZATION
This visualization maps the core traffic flow from the internet gateway through application load balancers into isolated Kubernetes namespaces. It highlights the separation of stateful and stateless components, internal service routing, and the GitOps deployment synchronization layer.
DEPLOYMENT PIPELINES — 4 TOTAL
Jenkins Shared Library — CI
Centralizes CI automation across all microservices. Multi-stage pipeline handles compilation, SAST security scans, image building, and vulnerability checks before pushing validated images to ECR. Ensures only tested, secure container artifacts reach deployment.
Push to feature branch
Pipeline auto-triggered
Code compilation check
Package validation
Quality & standards
SAST security check
Known CVE detection
Optimized image size
Container vuln scan
Verified image pushed
ArgoCD GitOps — CD
Establishes declarative delivery and drift detection. Polls Git for state changes, renders Helm charts, validates manifests, and syncs to EKS. Eliminates manual deployment errors, provides audit trail, and enables instant rollback.
New image available
Image tag in values.yaml
Manifest committed
Cluster vs Git diff
Last security check
Chart render & check
Pods to namespace
Liveness & readiness
Revert if failed
Cluster = Git state
Database Container Pipeline — 4 Instances
Provisions 4 StatefulSets (PostgreSQL, MongoDB, Redis, DynamoDB) with dedicated PVCs and automated backup policies. Each database serves a specific domain, minimizing cross-service data coupling.
Per service domain
Users, courses, enrollments
Content, media metadata
Cache, sessions, API
Events, notifications
Per DB persistent storage
Stable pod identity
Auto schedule per instance
Video Processing Pipeline — S3 + Lambda
Automates media processing via event-driven serverless architecture. S3 uploads trigger EventBridge, invoking Lambda functions for FFmpeg transcoding, thumbnail generation, and metadata extraction. Delivers multi-resolution HLS/DASH streams.
Raw video input bucket
Upload event fired
Format, size, codec check
1080p, 720p, 480p
Key frame thumbnails
Duration, resolution, codec
HLS/DASH segments
Downstream services notified
Video record written
Status tracked end-to-end
MICROSERVICES ARCHITECTURE
48 Services DesignedCore Platform
Manages identity, access control, and centralized API routing.
Learning & Content
Handles educational workflows, curriculum delivery, and student progress tracking.
Media & Streaming
Powers video delivery, document processing, and live streaming capabilities.
Communication
Facilitates messaging, notifications, and community interactions.
Payments & Business
Handles payment processing, subscription management, and billing logic.
Analytics & Intelligence
Aggregates telemetry, user behavior data, and powers internal search.
Platform & Operations
Supports feature toggling, audit logging, and cross-system integrations.
ARCHITECTURE DECISIONS
Single-AZ over Multi-AZ Setup
Opted for single Availability Zone to focus on validating orchestration patterns without the cost overhead of multi-AZ replication. This reduced AWS spend significantly while still demonstrating full CI/CD, monitoring, and deployment workflows.
GitOps Strategy over Imperative kubectl
Selected ArgoCD-driven GitOps to enforce infrastructure immutability. Every cluster state change is version-controlled in Git, providing a full audit trail, preventing configuration drift, and enabling deterministic rollbacks.
Jenkins Pipeline over Managed CI/CD
Self-hosted Jenkins with a custom Shared Library provided full control over build environments, plugin selection, and local container caching — trade-offs worth the additional compute management overhead.
Terraform Modularity over Monolithic Config
Decoupled infrastructure into separate Terraform modules (VPC, EKS, NodeGroups, IAM). This enabled rapid iteration — individual components could be modified and tested independently without affecting the rest of the stack.
CHALLENGES & SOLUTIONS
Observability across 48 services
Operating dozens of services created fragmented logs and isolated metrics, making incident triage difficult.
Deployed a centralized Prometheus + Grafana stack with per-namespace dashboards and alerting rules.
Enabled quick correlation of health probe failures and network issues.
Controlling AWS costs during testing
Dense microservice deployments escalated cloud spend during validation windows.
Constrained the cluster to single-AZ, integrated EC2 Spot instances, and built automated Terraform destroy scripts for post-testing cleanup.
Kept total runtime costs under budget.
Inter-service DNS resolution failures
Complex network policies blocked legitimate API calls across namespaces.
Debugged CoreDNS resolution chains and recalibrated overly restrictive Calico network policies.
Restored internal service discovery while maintaining security boundaries.
GitOps drift from manual debugging
Ad-hoc manual cluster changes during debugging caused sync conflicts with the Git state.
Enforced a strict GitOps-only policy, removing all direct cluster mutation permissions.
Eliminated undocumented drift entirely.
KEY LEARNINGS
Resource governance is non-negotiable at scale
Running many services reinforced that stability depends on proper namespace segmentation, RBAC policies, network policies, and resource quotas. Constraints must be set proactively, not reactively after failures.
GitOps changes how you think about deployments
With ArgoCD, the workflow shifts from 'deploying to a cluster' to 'declaring desired state in Git.' This made deployments predictable, auditable, and safely reversible.
Observability is a prerequisite, not an add-on
Managing distributed services without centralized metrics and logging is effectively flying blind. Prometheus + Grafana integration must be part of the initial architecture, not bolted on later.
Modular IaC accelerates iteration
Decoupling Terraform into modules meant I could tear down and rebuild individual components (networking, compute, IAM) independently. This dramatically sped up staging validation cycles.
FULL TECH STACK
Build. Deploy. Learn. Repeat.
Learning Hub
REACT / NODEFull-stack containerized app with microservices architecture and reverse proxy routing via Nginx.
Deployment
Docker + Nginx
Learned
- •Container networking
- •Reverse proxy config
- •Multi-service Docker
Links
Interior Designer
NEXT.JSServer-side rendered application with automated preview deployments triggered on each pull request via Vercel.
Deployment
Vercel CI/CD
Learned
- •Automated deployments
- •Preview environments
- •Server-side rendering
Links
Restaurant Site
HTML / JSStatic site hosted on S3 with CloudFront distribution, custom domain, and SSL certificate configured.
Deployment
S3 + CloudFront
Learned
- •S3 Static Hosting
- •CDN Distribution
- •SSL/TLS Management
Links
SaaS Prototype
NEXT.JS / POSTGRESServerless container deployment using ECS Fargate with a managed RDS backend, ALB routing, and auto-scaling.
Deployment
ECS Fargate
Learned
- •Serverless containers
- •Managed databases
- •Load balancer routing
Links
Portfolio v1
GATSBYJAMstack site with an automated GitHub Actions pipeline handling builds and deployments on each commit.
Deployment
GitHub Pages
Learned
- •GitHub Actions
- •JAMstack concepts
- •Automated releases
Links
Portfolio v2
NEXT.JS / TAILWINDEdge-deployed Next.js site using incremental static regeneration and image optimization for fast global delivery.
Deployment
Vercel Edge
Learned
- •Edge computing
- •Image optimization
- •ISR caching strategies
Links
Momentum
CURRENT SPRINT
Platform Reliability
Reviewing and improving platform configurations to support consistent service availability and operational stability.
Deployment Safety
Applying staged rollout strategies, canary deployments, and automated rollback to reduce risk during releases.
Kubernetes Operations
Building deeper knowledge of cluster management, scheduling, and networking across Kubernetes environments.
CI/CD Feedback Loops
Improving build and test feedback cycles to detect issues earlier and speed up the delivery process.
Collaboration
ECOSYSTEM
Professional Presence & Platforms
Participating in DevOps and cloud infrastructure communities, reviewing architectural decisions, and studying real-world production incidents and post-mortems.
Growth Strategy
INITIATE
CONTACT
Open to DevOps and Infrastructure Engineering opportunities.
Open to opportunities in DevOps, Platform Engineering, Cloud Infrastructure, and Site Reliability Engineering roles.